ここでは、第 28 回 GeneXus Meeting で行われた GeneXusAI の概念実証について説明します。
 サンプル - GeneXusAI PoC サンプル - GeneXusAI PoC
サンプル - GeneXusAI PoC (GeneXus 16 Upgrade 8 まで)
注: GeneXusAI_Sample.xpz ファイルをナレッジベースにインポートする前に、GeneXusAI の組み込みモジュールをインストールすることが重要です。
1. GeneXus ツールバーから [ ナレッジマネージャ ] オプションを選択します。
2. [ 参照モジュールの管理 ] をクリックします。
3. 表示されるリストで GeneXusAI モジュールを探します。
4. [ インストール ] ボタンをクリックします。
インストールプロセスは、 [ 出力 ] セクションの [ General ] オプションで確認できます。インストールされたら、ナレッジマネージャのインポート機能を使用して GeneXusAI_Sample.xpz ファイルをインポートできます。
ナレッジベースには次の内容が含まれます:
- GXAI_SD メニュー
メインオブジェクトであり、3 つのタブから構成されます。
- Panels フォルダ
- Utilities フォルダ
- GetProvider プロシージャー: プロバイダー構成を名前で取得します。
- SquareRegions プロシージャー: 長方形の領域 (OutputRegion データタイプ) を正方形に変換します (このサンプルに含まれる outputSquare データタイプに基づく)。これは、DetectFaces と OCR で検出領域を描画する際に使用されます。描画には、Grid コントロール上で SD Image Map コントロールが使われます。
- AddDelay 関数: SpeechToText の出力語句を 1 語ずつ表示するために使用される簡単な関数です。
- GetBlobUrl プロシージャー: 入力として Blob を受け取り、サーバー側の URL を取得するヘルパー関数です。このオブジェクトは既定では使用されません。この目的の詳細については、「注」を参照してください。
このアプリケーションは、ある GeneXusAI タスクの簡単な概念実証です。3 つのタブがあり、それぞれ使用可能なサブモジュールを表します: Audio、Image、Text。
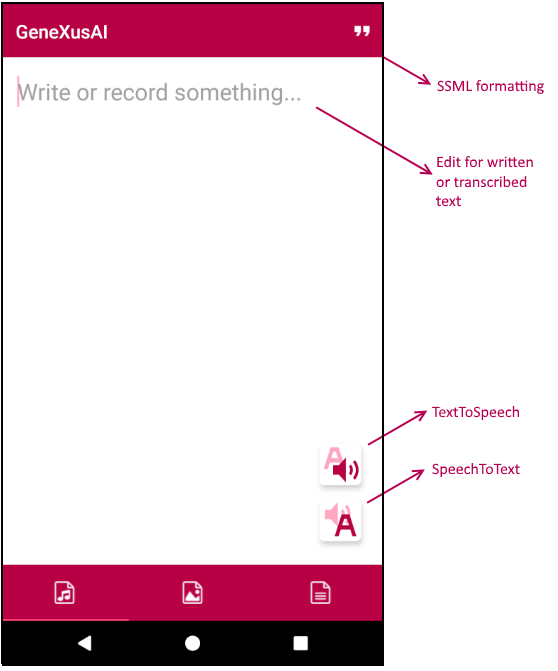 |
最初のタブでは、Audio モジュールのタスクを実行できます: SpeechToText プロシージャーと TextToSpeech プロシージャー。
ユーザーとしてテキストを入力し、TextToSpeech ボタンをタップすると、音声が合成され、それを聞くことができます。同様に、SpeechToText ボタンを使って音声を録音し、それを文字に起こすことができます。テキストは、テキストを入力する場合と同じ編集フィールドに表示されます。TextToSpeech では、SSML タグを使用して入力テキストの書式を設定できます。テキストの一部をクリップボードにコピーしたら、右上の引用符ボタンをタップし、いくつかのタグ (prosody や say-as) を使ってテキストの書式を設定できます。聞いてみると、出力される音声の変化がわかります。
このパネルでは、GeneXusAI に加え、Audio と AudioRecorder の各外部オブジェクトのみを使用して、オーディオストリームが再生、記録されます。アプリケーションにとって魅力的なエフェクトが 2 つあります: 1) オーディオの記録/再生の進捗と、2) 1 語ずつの結果表示です。
|
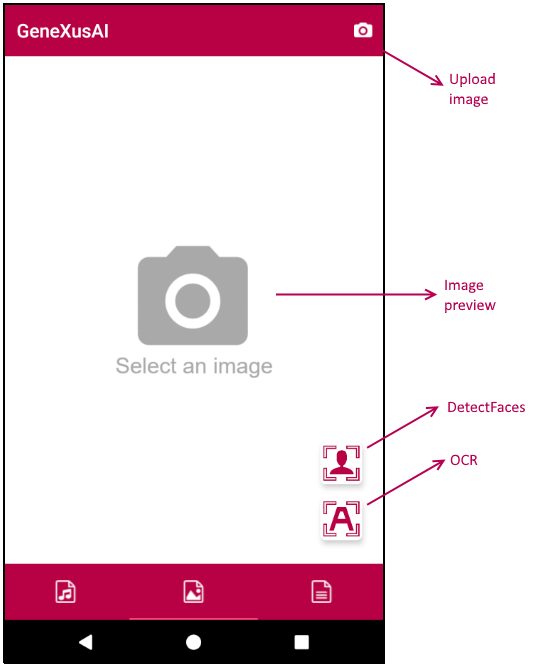 |
この 2 つ目のタブでは、Image モジュールのタスクを 2 つ実行できます: DetectFaces プロシージャーと OCR プロシージャー。
ユーザーとして、最初に写真を撮るか、ギャラリーから写真を選択します。画面に表示されたら、DetectFaces または OCR のタスクを対応するボタンから実行すると、画像内の顔やテキストを認識できます。
このパネルは、Camera と PhotoLibrary の各外部オブジェクトを使用して画像をアップロードするだけでなく、SD Image Map コントロールを使用して背景画像 (この例では写真) の上に長方形を描画します。これらのコントロールの制限事項により、GeneXusAI から取得される長方形の領域 (上、左、幅、高さ) は、元の長方形に合った正方形 (上、左、サイズ) に変換されます。また、このパネルでは、顔/テキストのタグの内容で編集できます (ソーシャルメディアでの写真のタグ付けと同様)。
|
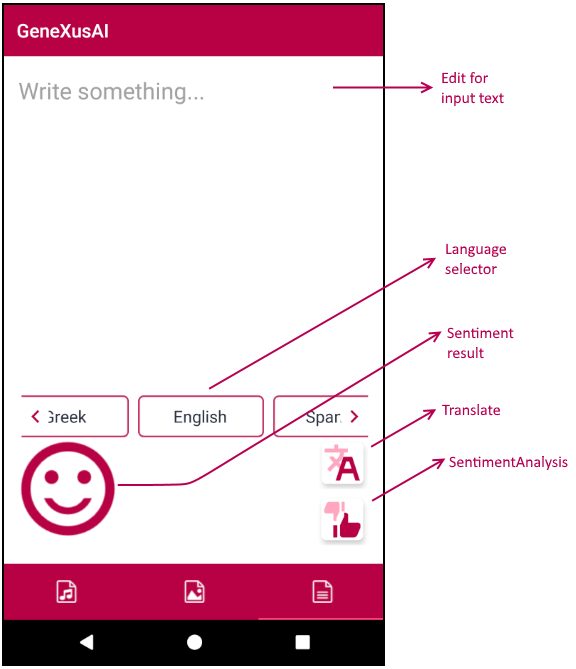 |
この 3 つ目のタブでは、Text モジュールのタスクを 3 つ実行できます: DetectLanguage プロシージャー、Translate プロシージャー、SentimentAnalysis プロシージャー。
ユーザーとしてテキストを入力し、 [ Translate ] ボタンをタップすると、翻訳する言語を表示できます。また、上向き/下向きの親指のボタンをタップすると、入力に対する感情を分析できます。結果は、うれしい顔 (スコアが 0.5 を上回る場合)、悲しい顔 (スコアが 0.5 を下回る場合)、あるいは同時に両方 (スコアがちょうど 0.5 だった場合) になります。翻訳では、DetectLanguage プロシージャーが自動的に呼び出され、テキストが入力された言語が特定されます。
|
|